概述
用户可以使用 ql 语言编写自定义规则识别软件中的漏洞,也可以使用ql自带的规则进行扫描
环境搭建
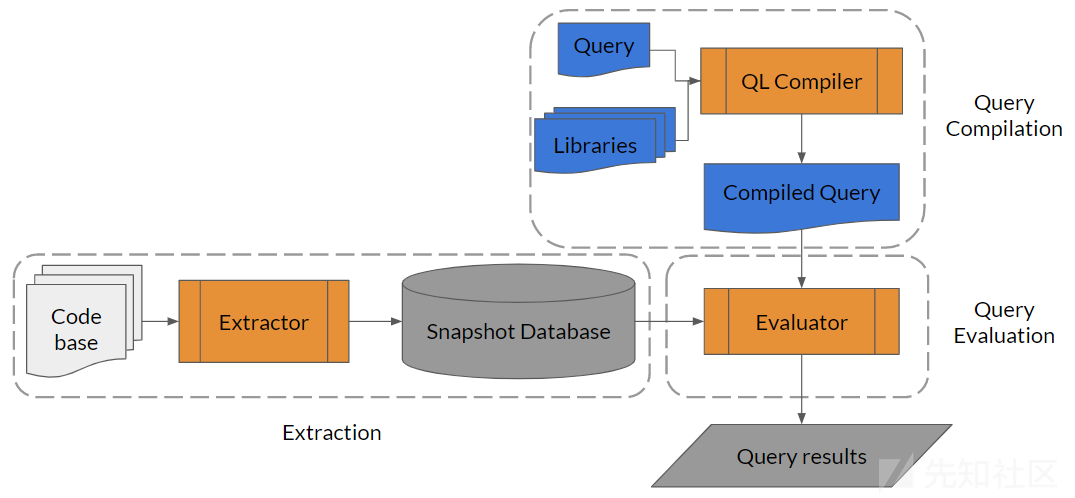
codeql的工作方式是首先使用codeql来编译源码,从源码中搜集需要的信息,然后将搜集到的信息保存为代码数据库文件,用户通过编写codeql规则从数据库中搜索出匹配的代码,工作示意图如下:
 20210307124958-91ad19fe-7f00-1
20210307124958-91ad19fe-7f00-1
在github release下载二进制安装包 vscode下载插件
再clone一下这个:codeql starter,打开工作区
首先使用codeql编译代码并创建数据库
ayoung@LAPTOP-1J0VDV39:~/codeql/vscode-codeql-starter/codeql-custom-queries-cpp$ codeql database create --language=cpp -c "gcc hello.c -o hello" ./hello_codedb Initializing database at /home/ayoung/codeql/vscode-codeql-starter/codeql-custom-queries-cpp/hello_codedb. Running build command: [gcc, hello.c, -o, hello] Finalizing database at /home/ayoung/codeql/vscode-codeql-starter/codeql-custom-queries-cpp/hello_codedb. Successfully created database at /home/ayoung/codeql/vscode-codeql-starter/codeql-custom-queries-cpp/hello_codedb.
然后就可以在vscode用插件加载数据库。在linux上创建数据库,在windows平台加载数据库并进行查询,故还需要将数据库打包(如果都在linux上进行则不需要此步骤)
ayoung@LAPTOP-1J0VDV39:~/codeql/vscode-codeql-starter/codeql-custom-queries-cpp$ codeql database bundle -o hello_codedb.zip hello_codedb Creating bundle metadata for /home/ayoung/codeql/vscode-codeql-starter/codeql-custom-queries-cpp/hello_codedb... Creating zip file at /home/ayoung/codeql/vscode-codeql-starter/codeql-custom-queries-cpp/hello_codedb.zip.
最后点击codeql插件,上方databases点击from folder即可打开数据库
另外如果不想用starter,想单独配置工作区,则工作区右键add folder to workspace添加ql库,同时workspace里要有一个qlpack.yml,内容为
name: name/example version: 0.0.0 libraryPathDependencies: codeql/cpp-all
demo
下面示例代码用的https://github.com/hac425xxx/sca-workshop/tree/master/ql-example
import 语句可以导入需要的库,库里面会封装一些函数、类供我们使用
from 语句用于定义查询中需要使用的变量
where 语句用于设置变量需要满足的条件
select 语句则用于将结果显示,可以选择结果中需要输出的东西
system命令注入
查询函数名
import cpp from FunctionCall fc select fc.getTarget().getQualifiedName(), fc
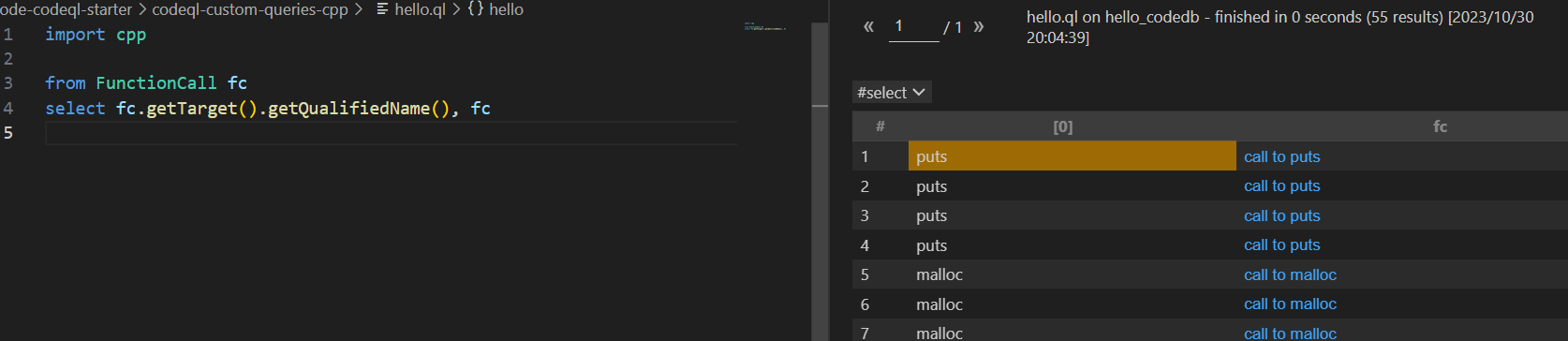 image-20231030200454359
image-20231030200454359
查询内部调用了system的函数
import cpp from FunctionCall fc where fc.getTarget().getName().matches("system") select fc.getEnclosingFunction(), fc
 image-20231030200512007
image-20231030200512007
查询内部调用了system的且system参数不为常量
import cpp from FunctionCall fc where fc.getTarget().getName().matches("system") and not fc.getArgument(0).isConstant() select fc.getEnclosingFunction(), fc, fc.getArgument(0)
 image-20231030200535186
image-20231030200535186
fc查找调用system的函数,clean_fc查找调用了clean_data的函数,然后排除这两个函数处于同一个函数下的函数
import cpp from FunctionCall fc, FunctionCall clean_fc where fc.getTarget().getName().matches("system") and not fc.getArgument(0).isConstant() and clean_fc.getTarget().getName().matches("clean_data") and not clean_fc.getEnclosingFunction() = fc.getEnclosingFunction() select fc.getEnclosingFunction(), fc, fc.getArgument(0)
 image-20231030201741093
image-20231030201741093
解决误报,启用污点跟踪 污点跟踪由 TaintTracking 模块提供,codeql 支持 local 和 global 两种污点追踪模块,区别在于 local 的污点追踪只能追踪函数内的代码,函数外部的不追踪,global 则会在整个源码工程中对数据进行追踪
查询解释如下: 首先定义了两个函数调用 system_call 和 user_input ,分别表示调用 system 和 get_user_input_str 的函数调用表达式 然后定义 source 和 sink 作为污点跟踪的 source 和 sink 点 然后利用 sink.asExpr() = system_call.getArgument(0) 设置 sink 点为 system 函数调用的第一个参数 然后利用 source.asExpr() 设置 sink 点为 get_user_input_str 函数调用的第一个参数 最后使用 TaintTracking::localTaint 查找从 source 到 sink 的查询 (也就是说去找 获取用户输入,并把输入传给system 这么个模式)
import cpp import semmle.code.cpp.dataflow.TaintTracking from FunctionCall system_call, FunctionCall user_input, DataFlow::Node source, DataFlow::Node sink where system_call.getTarget().getName().matches("system") and user_input.getTarget().getName().matches("get_user_input_str") and sink.asExpr() = system_call.getArgument(0) and source.asExpr() = user_input and TaintTracking::localTaint(source, sink) select user_input, user_input.getEnclosingFunction()
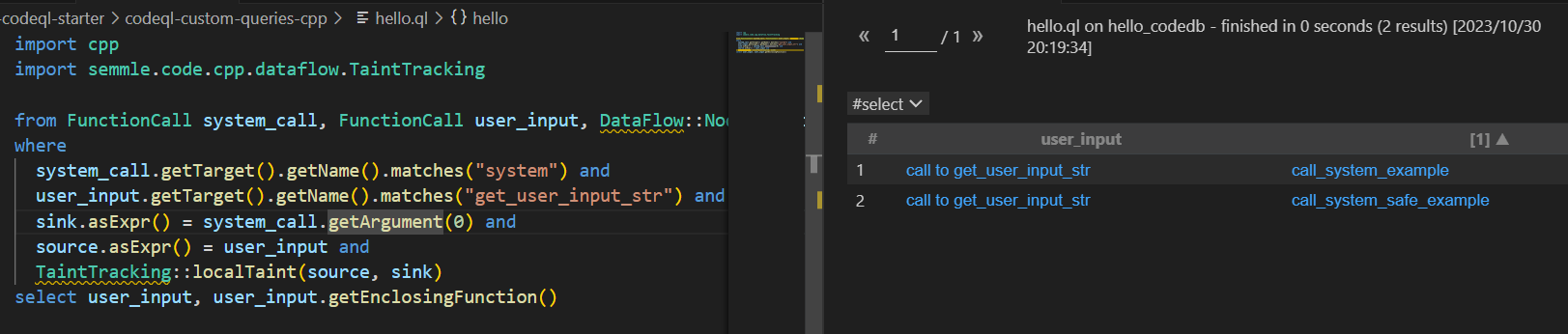 image-20231030203028577
image-20231030203028577
用localTaint可能有漏报,可能是our_wrapper_system()
也有误报因为中间可能被clean了
先处理没有考虑our_wrapper_system的情况,一种方法是把 our_wrapper_system 也考虑进 sink 点
import cpp import semmle.code.cpp.dataflow.TaintTracking predicate setSystemSink(FunctionCall fc, Expr e) { fc.getTarget().getName().matches("system") and fc.getArgument(0) = e } predicate setWrapperSystemSink(FunctionCall fc, Expr e) { fc.getTarget().getName().matches("our_wrapper_system") and fc.getArgument(0) = e } from FunctionCall fc, FunctionCall user_input, DataFlow::Node source, DataFlow::Node sink where ( setWrapperSystemSink(fc, sink.asExpr()) or setSystemSink(fc, sink.asExpr()) ) and user_input.getTarget().getName().matches("get_user_input_str") and sink.asExpr() = fc.getArgument(0) and source.asExpr() = user_input and TaintTracking::localTaint(source, sink) select user_input, user_input.getEnclosingFunction()
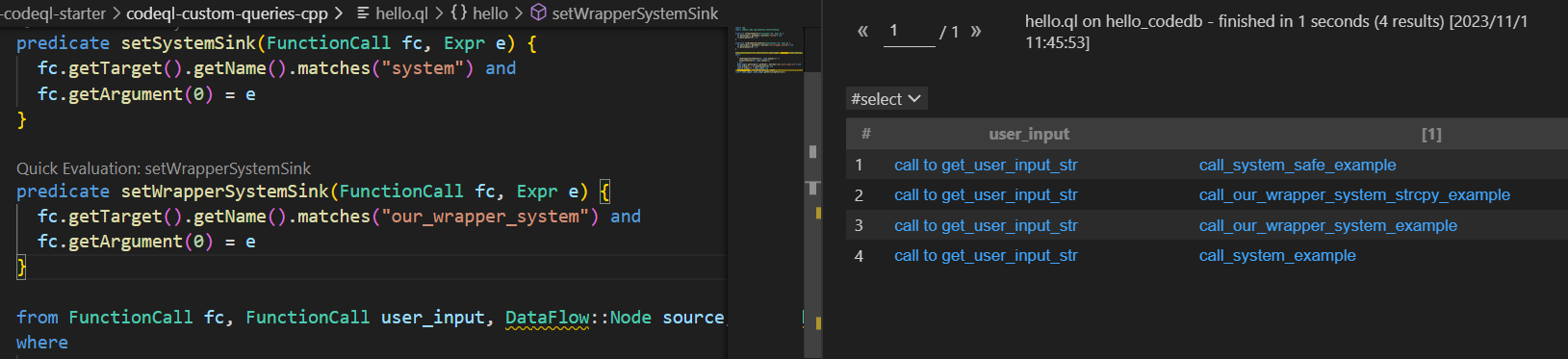 image-20231101114622620
image-20231101114622620
或者用global taint 要使用 global taint 需要定义一个类继承自 TaintTracking::Configuration ,然后重写 isSource 和 isSink isSource 用于定义 source 点,指定 get_user_input_str 的函数调用为 source 点 isSink 定义 sink 点,指定 system 的一个参数为 sink 点 然后在 where 语句里面使用 cfg.hasFlowPath(source, sink) 查询到从 source 到 sink 的代码
import cpp import semmle.code.cpp.dataflow.TaintTracking class SystemCfg extends TaintTracking::Configuration { SystemCfg() { this = "SystemCfg" } override predicate isSource(DataFlow::Node source) { source.asExpr().(FunctionCall).getTarget().getName() = "get_user_input_str" } override predicate isSink(DataFlow::Node sink) { exists(FunctionCall call | sink.asExpr() = call.getArgument(0) and call.getTarget().getName() = "system" ) } } from DataFlow::PathNode sink, DataFlow::PathNode source, SystemCfg cfg where cfg.hasFlowPath(source, sink) select source, sink
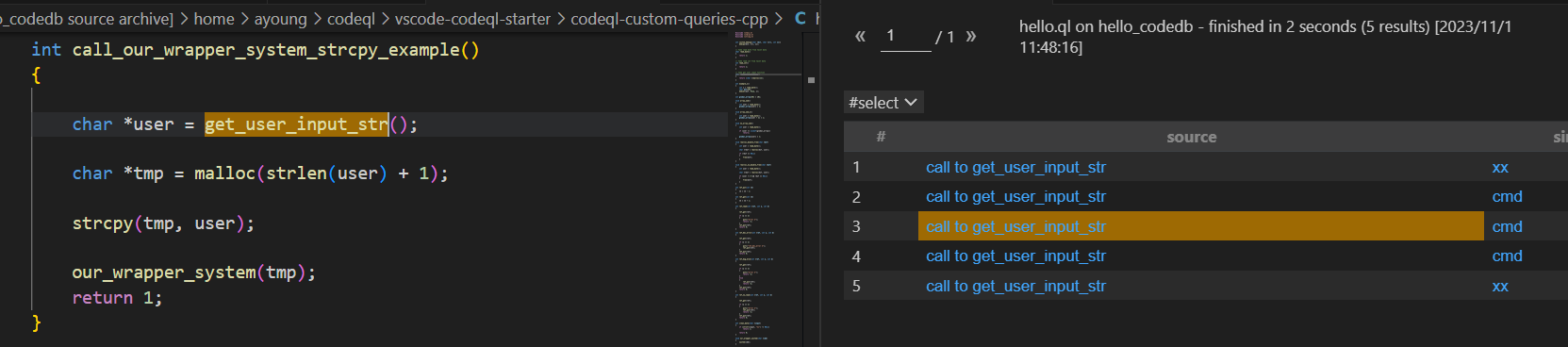 image-20231101114955835
image-20231101114955835
然后发现call_system_safe_example函数还是被测出来了,可以通过isSanitizer函数剔除污点数据流入clean_data
用到global value numbering
import cpp import semmle.code.cpp.dataflow.TaintTracking import semmle.code.cpp.valuenumbering.GlobalValueNumbering class SystemCfg extends TaintTracking::Configuration { SystemCfg() { this = "SystemCfg" } override predicate isSource(DataFlow::Node source) { source.asExpr().(FunctionCall).getTarget().getName() = "get_user_input_str" } override predicate isSink(DataFlow::Node sink) { exists(FunctionCall call | sink.asExpr() = call.getArgument(0) and call.getTarget().getName() = "system" ) } override predicate isSanitizer(DataFlow::Node nd) { exists(FunctionCall fc | fc.getTarget().getName() = "clean_data" and globalValueNumber(fc.getArgument(0)) = globalValueNumber(nd.asExpr()) ) } } from DataFlow::PathNode sink, DataFlow::PathNode source, SystemCfg cfg where cfg.hasFlowPath(source, sink) select source, sink
数组越界
漏洞代码
int global_array[40] = {0}; void array_oob() { int user = read_byte(); global_array[user] = 1; }
漏洞模型:污点跟踪查询,source点是read_byte()的调用,sink点是污点数据被用作数组索引
import cpp import semmle.code.cpp.dataflow.TaintTracking class ArrayOOBCfg extends TaintTracking::Configuration { ArrayOOBCfg() { this = "ArrayOOBCfg" } override predicate isSource(DataFlow::Node source) { source.asExpr().(FunctionCall).getTarget().getName() = "read_byte" } override predicate isSink(DataFlow::Node sink) { exists(ArrayExpr ae | sink.asExpr() = ae.getArrayOffset()) } } from DataFlow::PathNode sink, DataFlow::PathNode source, ArrayOOBCfg cfg where cfg.hasFlowPath(source, sink) select source.getNode().asExpr().(FunctionCall).getEnclosingFunction(), source, sink
source.asExpr().(FunctionCall).getTarget().getName() = "read_byte",让source为read_byte的FunctionCall语句,其中.(FunctionCall)类似强制转换
sink点查询:ql中很多语法结构都有对应的类来表示,比如这里涉及的数组访问可以通过ArrayExpr对象获取,getArrayOffset()获取偏移,getArrayBase()获取数组基地址
import cpp from ArrayExpr ae select ae, ae.getArrayOffset(), ae.getArrayBase()
发现查到一个误报
void no_array_oob() { int user = read_byte(); if (user >= sizeof(global_array)) return; global_array[user] = 1; }
进行过滤,这里就简单的认为用户输入进入 if 语句的条件判断中就认为用户输入被正确的校验了。codeql 使用 IfStmt 来表示一个 if 语句,然后使用 getControllingExpr 可以获取到 if 语句的控制语句部分,然后我们使用 getAChild* 递归的遍历控制语句的所有子节点,只要有 nd 为控制语句中的一部分就返回true。
override predicate isSanitizer(DataFlow::Node nd) { exists(IfStmt ifs | globalValueNumber(ifs.getControllingExpr().getAChild*()) = globalValueNumber(nd.asExpr()) ) }
引用计数相关
漏洞代码
int ref_leak(int *ref, int a, int b) { ref_get(ref); if (a == 2) { puts("error 2"); return -1; } ref_put(ref); return 0; }
漏洞是当 a=2 时会直接返回,没有调用 ref_put 对引用计数减一,漏洞模型:在某些存在 return的条件分支中没有调用 ref_put 释放引用计数。
查询代码如下
import cpp import semmle.code.cpp.dataflow.TaintTracking class RefGetFunctionCall extends FunctionCall { RefGetFunctionCall() { this.getTarget().getName() = "ref_get" } } class RefPutFunctionCall extends FunctionCall { RefPutFunctionCall() { this.getTarget().getName() = "ref_put" } } class EvilIfStmt extends IfStmt { EvilIfStmt() { exists(ReturnStmt rs | this.getAChild*() = rs and not exists(RefPutFunctionCall rpfc | rpfc.getEnclosingBlock() = rs.getEnclosingBlock()) ) } } from RefGetFunctionCall rgfc, EvilIfStmt eifs where eifs.getEnclosingFunction() = rgfc.getEnclosingFunction() select eifs.getEnclosingFunction(), eifs
代码使用类来定义某个特定的函数调用,比如 RefPutFunctionCall 用于表示调用 ref_put 函数的函数调用语句 用EvilIfStmt表示存在returnd但没有调用ref_put的代码
首先用this.getAChild*() = rs约束this为一个包含return语句的if结构
然后加上一个exists确保和rs同一个块的语句里没有return语句
漏洞代码二
int ref_dec_error(int *ref, int a, int b) { ref_get(ref); if (a == 2) { puts("ref_dec_error 2"); ref_put(ref); } ref_put(ref); return 0; }
a==2调用ref_put了,但没有return
漏洞模型:某些条件分支中调用ref_put释放引用计数,但没有return返回。可能导致ref_put多次
查询代码如下
import cpp import semmle.code.cpp.dataflow.TaintTracking class RefGetFunctionCall extends FunctionCall { RefGetFunctionCall() { this.getTarget().getName() = "ref_get" } } class RefPutFunctionCall extends FunctionCall { RefPutFunctionCall() { this.getTarget().getName() = "ref_put" } } class EvilIfStmt extends IfStmt { EvilIfStmt() { exists(RefPutFunctionCall rpfc | this.getAChild*() = rpfc and not exists(ReturnStmt rs | rpfc.getEnclosingBlock() = rs.getEnclosingBlock()) ) } } from RefGetFunctionCall rgfc, EvilIfStmt eifs where eifs.getEnclosingFunction() = rgfc.getEnclosingFunction() select eifs.getEnclosingFunction(), eifs
只有类EvilIfStmt发生了变动,其中首先约束语句包含refput,然后要求不存在return
外部函数建模
静态污点分析的常见问题当数据流入外部函数(比如没有源码的库函数)中时污点分析引擎就可能会丢失污点传播信息
int custom_memcpy(char *dst, char *src, int sz); int call_our_wrapper_system_custom_memcpy_example() { char *user = get_user_input_str(); char *tmp = malloc(strlen(user) + 1); custom_memcpy(tmp, user, strlen(user)); our_wrapper_system(tmp); return 1; }
直接使用ql查询会发现查询不到这个代码,因为custom_memcpy是一个外部函数,code的污点跟踪引擎无法知道污点传播规则
解决方法:
- 重写
isAdditionalTainStep函数
使用 TaintTracking::Configuration 时可以通过重写 isAdditionalTaintStep 函数来自定义污点传播规则
override predicate isAdditionalTaintStep(DataFlow::Node pred, DataFlow::Node succ) { exists(FunctionCall fc | pred.asExpr() = fc.getArgument(1) and fc.getTarget().getName() = "custom_memcpy" and succ.asDefiningArgument() = fc.getArgument(0) ) }
isAdditionalTaintStep:返回true表示污点从pred流入succ
指定custom的第1个参数src流入第0个参数dst
asExpr(),匹配函数参数 asDefiningArgument(),当调用返回后引用参数的值时使用 (?)
- 给ql源码增加模型
在ql的源码里面内置很多标准库函数的模型,比如strcpy,memcpy 等,代码路径为cpp\ql\src\semmle\code\cpp\models\implementations\Memcpy.qll
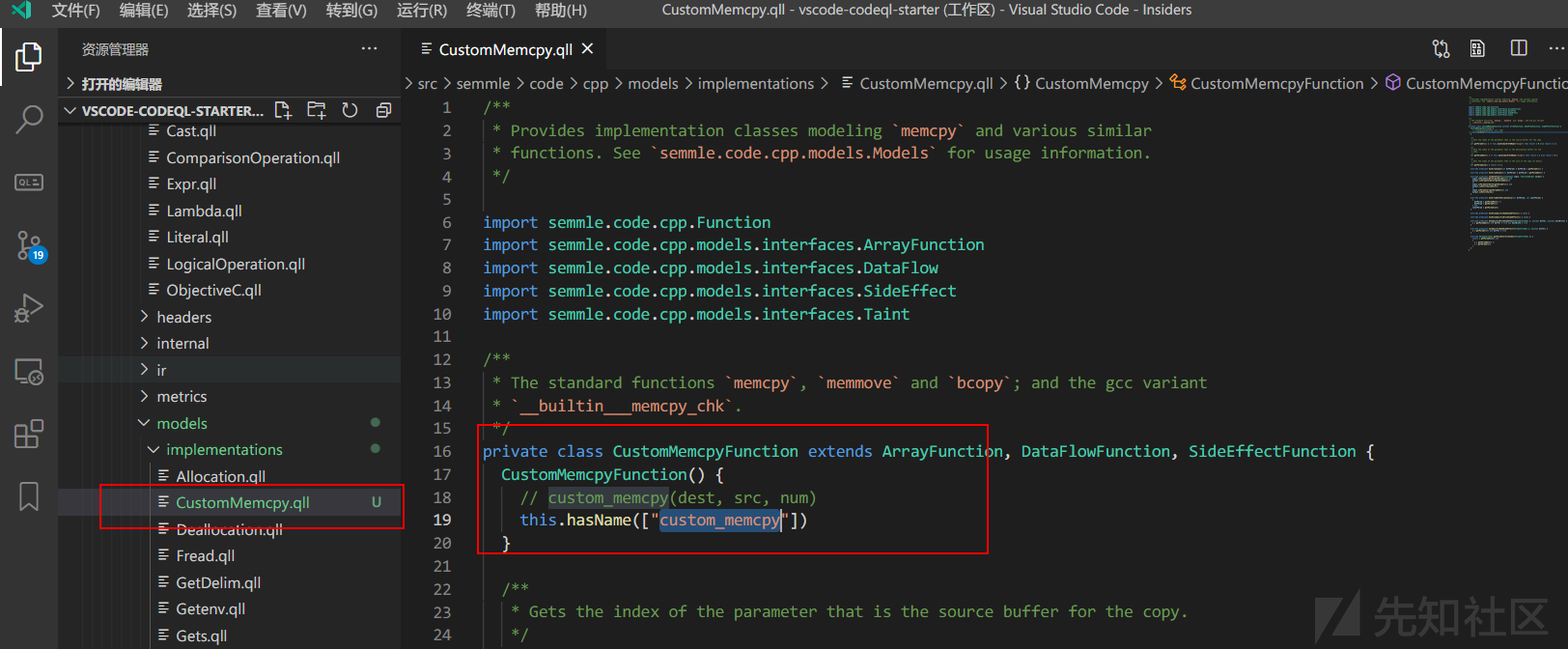
可以在此处新建一个.qll文件
然后在Models.qll里面private import导入一下即可
tutorial
谓词
predicate,可以无返回值也可以有返回值 无返回值声明
predicate isSmall(int i) { i in [1 .. 9] }
有返回值声明,需要声明返回值数据类型
int getSuccessor(int i) { // 若传入的i位于1-9内,则返回i+1 // 注意这个语法不能用C++语法来理解 result = i + 1 and i in [1 .. 9] }
可能返回多个结果或不返回结果
string getANeighbor(string country) { country = "France" and result = "Belgium" or country = "France" and result = "Germany" or country = "Germany" and result = "Austria" or country = "Germany" and result = "Belgium" } select getANeighbor("France") // 返回两个条目,"Belgium"与"Germany"
不允许描述的数据集合个数不是有限数量大小
// 该谓词将使得编译报错 int multiplyBy4(int i) { // i是一个数据集合,此时该集合可能是**无限大小** // result集合被设置为i*4,意味着result集合的大小有可能也是**无限大小** result = i * 4 }
如果仍需定义这类函数,则必须限制集合数据大小,同时添加一个bindingset标注。该标注将会声明谓词plusOne所包含的数据集合是有限的,前提是绑定到有限数量的数据集合。
bindingset[x] bindingset[y] predicate plusOne(int x, int y) { x + 1 = y } from int x, int y where y = 42 and plusOne(x, y) select x, y
递归
Person ancestorOf(Person p) { result = parentOf(p) or result = parentOf(ancestorOf(p)) }
parentOf+(p) applies the parentOf() predicate to p one or more times. This is equivalent to ancestorOf(p). parentOf*(p) applies the parentOf() predicate to p zero or more times, so it returns an ancestor of p or p itself.
parentOf+(p)将函数用在p上一次或多次,等于ancestorOf(p)(传递闭包)
parentOf*(p)将函数用在p上0或多次,返回p的祖先或p自己(自反传递闭包)
类
类名开头需要是大写
一个用codeql解决的路径规划问题,将货物从左岸搬到右岸,通过递归直接得到可能的路径(不重复且符合约束条件,例如山羊和狼不同时在一起)
import tutorial /** A possible cargo item. */ class Cargo extends string { Cargo() { this = "Nothing" or this = "Goat" or this = "Cabbage" or this = "Wolf" } } /** One of two shores. */ class Shore extends string { Shore() { this = "Left" or this = "Right" } /** Returns the other shore. */ Shore other() { this = "Left" and result = "Right" or this = "Right" and result = "Left" } } string renderState(Shore manShore, Shore goatShore, Shore cabbageShore, Shore wolfShore) { result = manShore + "," + goatShore + "," + cabbageShore + "," + wolfShore } /** A record of where everything is. */ class State extends string { Shore manShore; Shore goatShore; Shore cabbageShore; Shore wolfShore; /** Renders the state as a string. */ State() { this = manShore + "," + goatShore + "," + cabbageShore + "," + wolfShore } /** Returns the state that is reached after ferrying a particular cargo item. */ State ferry(Cargo cargo) { cargo = "Nothing" and result = renderState(manShore.other(), goatShore, cabbageShore, wolfShore) or cargo = "Goat" and result = renderState(manShore.other(), goatShore.other(), cabbageShore, wolfShore) or cargo = "Cabbage" and result = renderState(manShore.other(), goatShore, cabbageShore.other(), wolfShore) or cargo = "Wolf" and result = renderState(manShore.other(), goatShore, cabbageShore, wolfShore.other()) } /** * Holds if the state is safe. This occurs when neither the goat nor the cabbage * can get eaten. */ predicate isSafe() { // The goat can't eat the cabbage. (goatShore != cabbageShore or goatShore = manShore) and // The wolf can't eat the goat. (wolfShore != goatShore or wolfShore = manShore) } State reachesVia(string path, string visitedStates){ this = result and visitedStates = this and path = "" or exists(string pathSofar, string vstateSofar, Cargo cargo | result = this.reachesVia(pathSofar, vstateSofar).safeFerry(cargo) and not exists(vstateSofar.indexOf(result)) and visitedStates = vstateSofar + "/" + result and path = pathSofar + "\n Ferry " + cargo +" " + result + "\n" ) } /** Returns the state that is reached after safely ferrying a cargo item. */ State safeFerry(Cargo cargo) { result = this.ferry(cargo) and result.isSafe() } } /** The initial state, where everything is on the left shore. */ class InitialState extends State { InitialState() { this = "Left" + "," + "Left" + "," + "Left" + "," + "Left" } } /** The goal state, where everything is on the right shore. */ class GoalState extends State { GoalState() { this = "Right" + "," + "Right" + "," + "Right" + "," + "Right" } } from string path where any(InitialState i).reachesVia(path, _) = any(GoalState g) select path
GitHub Security Lab CTF
SEGV hunt
首先下载设计题目时对应的glibc数据库 revision 3332218,然后导入
intro
alloca用来在栈上申请缓冲区,然而当申请的大小过大时,可能返回一个无效指针,造成当尝试读写时触发SIGSEGV crash
Step 0: finding the definition of alloca
Question 0.0: alloca is a macro. Find the definition of this macro and the name of the function that it expands to.
import cpp from MacroInvocation mi where mi.getMacro().getName() = "alloca" select mi, mi.getEnclosingFunction()
Step 1: finding the calls to alloca and filtering out small allocation sizes
Question 1.0: Find all the calls to alloca (using the function name that you found in step 0). Question 1.1: Use the upperBound and lowerBound predicates from the SimpleRangeAnalysis library to filter out results which are safe because the allocation size is small. You can classify the allocation size as small if it is less than 65536. But don't forget that negative sizes are very dangerous.
upperbound和lowerbound的参数需要是expr
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } } from AllocaFunc af where af.notSafealloc() select af, af.getArgument(0)
step2 filtering out calls that are guarded by __libc_use_alloca
The correct way to use alloca in glibc is to first check that the allocation is safe by calling __libc_use_alloca. You can see a good example of this at getopt.c:252. That code uses __libc_use_alloca to check if it is safe to use alloca. If not, it uses malloc instead. In this step, you will identify calls to alloca that are safe because they are guarded by a call to __libc_use_alloca.
正确的方法是先用__libc_use_alloc检查申请是否安全,不安全时使用malloc代替
if (__libc_use_alloca (n_options)) ambig_set = alloca (n_options); else if ((ambig_set = malloc (n_options)) == NULL) /* Fall back to simpler error message. */ ambig_fallback = 1;
Question 2.0
Question 2.0: Find all calls to __libc_use_alloca.
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af, LibcUseAlloca lua select lua
Question 2.1
Question 2.1: Find all guard conditions where the condition is a call to __libc_use_alloca.
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af, LibcUseAlloca lua, GuardCondition gc where gc.controls(af.getBasicBlock(), _) and gc.getAChild*() = lua select gc
Question 2.2
Sometimes the result of __libc_use_alloca is assigned to a variable, which is then used as the guard condition. For example, this happens at setsourcefilter.c:38-41. Enhance your query, using local dataflow, so that it also finds this guard condition.
有时候__libc_use_alloca的返回值存到一个变量里,然后再用这个变量作为if条件判断。使用local dataflow增加query
int use_alloca = __libc_use_alloca (needed); struct group_filter *gf; if (use_alloca) gf = (struct group_filter *) alloca (needed); else { gf = (struct group_filter *) malloc (needed); if (gf == NULL) return -1; }
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards import semmle.code.cpp.dataflow.internal.DataFlowUtil import semmle.code.cpp.dataflow.new.DataFlow class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af, LibcUseAlloca lua, GuardCondition gc, DataFlow::Node source, DataFlow::Node sink where gc.controls(af.getBasicBlock(), _) and DataFlow::localFlow(source, sink) and source.asExpr() = lua and sink.asExpr() = gc select gc
Question 2.3
Sometimes the call to __libc_use_alloca is wrapped in a call to __builtin_expect. For example, this happens at setenv.c:185. Enhance your query so that it also finds this guard condition.
有时候__libc_use_alloca被包裹在__builtin_expect中,继续完善
int use_alloca = __libc_use_alloca (varlen); if (__builtin_expect (use_alloca, 1)) new_value = (char *) alloca (varlen); else { new_value = malloc (varlen); if (new_value == NULL) { UNLOCK; return -1; } }
改sink,只要guardcondition判断条件中涉及的都匹配,上个版本是要求完整匹配
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards import semmle.code.cpp.dataflow.internal.DataFlowUtil import semmle.code.cpp.dataflow.new.DataFlow class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af, LibcUseAlloca lua, GuardCondition gc, DataFlow::Node source, DataFlow::Node sink where gc.controls(af.getBasicBlock(), _) and DataFlow::localFlow(source, sink) and source.asExpr() = lua and sink.asExpr() = gc.getAChild*() select gc
Question 2.4
Sometimes the result of __libc_use_alloca is negated with the ! operator. For example, this happens at getaddrinfo.c:2291-2293. Enhance your query so that it can also handle negations.
malloc_results = !__libc_use_alloca (alloc_size); if (malloc_results) { results = malloc (alloc_size); if (results == NULL) { __free_in6ai (in6ai); return EAI_MEMORY; } } ...
source用basicblock的node,进而用contains限制basicblock,以及guardcondition的参数也直接改成b1
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards import semmle.code.cpp.dataflow.internal.DataFlowUtil import semmle.code.cpp.dataflow.new.DataFlow class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af, LibcUseAlloca lua, GuardCondition gc, DataFlow::Node source, DataFlow::Node sink, BasicBlock b1, BasicBlock b2 where gc.controls(b1, _) and b1.contains(af) and b2.contains(lua) and DataFlow::localFlow(source, sink) and source.asExpr() = b2.getANode() and sink.asExpr() = gc.getAChild*() select gc, source, sink
Question 2.5
Find calls to alloca that are safe because they are guarded by a call to __libc_use_alloca.
上述写成一个谓词
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards import semmle.code.cpp.dataflow.internal.DataFlowUtil import semmle.code.cpp.dataflow.new.DataFlow class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } predicate guardedByLUA() { exists( LibcUseAlloca lua, GuardCondition gc, DataFlow::Node source, DataFlow::Node sink, BasicBlock b1, BasicBlock b2 | gc.controls(b1, _) and b1.contains(this) and b2.contains(lua) and DataFlow::localFlow(source, sink) and source.asExpr() = b2.getANode() and sink.asExpr() = gc.getAChild*() ) } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af where af.guardedByLUA() select af
Step 3: combine steps 1 and 2 to filter out safe calls
Question 3.0
Question 3.0: use your answer from step 2 to enhance your query from step 1 by filtering out calls to alloca that are safe because they are guarded by a call to __libc_use_alloca.
import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards import semmle.code.cpp.dataflow.internal.DataFlowUtil import semmle.code.cpp.dataflow.new.DataFlow class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate notSafealloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } predicate guardedByLUA() { exists( LibcUseAlloca lua, GuardCondition gc, DataFlow::Node source, DataFlow::Node sink, BasicBlock b1, BasicBlock b2 | gc.controls(b1, _) and b1.contains(this) and b2.contains(lua) and DataFlow::localFlow(source, sink) and source.asExpr() = b2.getANode() and sink.asExpr() = gc.getAChild*() ) } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } from AllocaFunc af where af.guardedByLUA() and af.notSafealloc() select af
Step 4: taint tracking
Question 4.0: Find calls to fopen. (Be aware that fopen is another macro.) Question 4.0: Write a taint tracking query. The source should be a call to fopen and the sink should be the size argument of an unsafe call to alloca. To help you get started, here is the boilerplate for the query:
/** * @name 41_fopen_to_alloca_taint * @description Track taint from fopen to alloca. * @kind path-problem * @problem.severity warning */ import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.dataflow.TaintTracking import semmle.code.cpp.models.interfaces.DataFlow import semmle.code.cpp.controlflow.Guards import DataFlow::PathGraph // Track taint through `__strnlen`. class StrlenFunction extends DataFlowFunction { StrlenFunction() { this.getName().matches("%str%len%") } override predicate hasDataFlow(FunctionInput i, FunctionOutput o) { i.isInParameter(0) and o.isOutReturnValue() } } // Track taint through `__getdelim`. class GetDelimFunction extends DataFlowFunction { GetDelimFunction() { this.getName().matches("%get%delim%") } override predicate hasDataFlow(FunctionInput i, FunctionOutput o) { i.isInParameter(3) and o.isOutParameterPointer(0) } } class Config extends TaintTracking::Configuration { Config() { this = "fopen_to_alloca_taint" } override predicate isSource(DataFlow::Node source) { // TODO } override predicate isSink(DataFlow::Node sink) { // TODO } } from Config cfg, DataFlow::PathNode source, DataFlow::PathNode sink where cfg.hasFlowPath(source, sink) select sink, source, sink, "fopen flows to alloca"
这里官方提到的taint tracking已废弃,使用新taint tracking
/** * @id ayoung * @name 41_fopen_to_alloca_taint * @description Track taint from fopen to alloca. * @kind path-problem * @problem.severity warning */ import cpp import semmle.code.cpp.rangeanalysis.SimpleRangeAnalysis import semmle.code.cpp.controlflow.Guards import semmle.code.cpp.dataflow.internal.DataFlowUtil import semmle.code.cpp.dataflow.new.DataFlow import semmle.code.cpp.dataflow.new.TaintTracking import semmle.code.cpp.models.interfaces.DataFlow import DataFlow::PathGraph class AllocaFunc extends FunctionCall{ AllocaFunc() { this.getTarget().hasName("__builtin_alloca") } predicate isOOBAlloc() { lowerBound(this.getArgument(0).getFullyConverted()) < 0 or upperBound(this.getArgument(0).getFullyConverted()) >= 65536 } predicate isGuardedByLUA() { exists( LibcUseAlloca lua, GuardCondition gc, DataFlow::Node source, DataFlow::Node sink, BasicBlock b1, BasicBlock b2 | gc.controls(b1, _) and b1.contains(this) and b2.contains(lua) and DataFlow::localFlow(source, sink) and source.asExpr() = b2.getANode() and sink.asExpr() = gc.getAChild*() ) } predicate isUnsafeAlloc(){ this.isOOBAlloc() and not this.isGuardedByLUA() } } class LibcUseAlloca extends FunctionCall{ LibcUseAlloca() { this.getTarget().hasName("__libc_use_alloca") } } class FopenFunc extends FunctionCall{ FopenFunc() { this.getTarget().hasName("_IO_new_fopen") } } // Track taint through `__strnlen`. class StrlenFunction extends DataFlowFunction { StrlenFunction() { this.getName().matches("%str%len%") } override predicate hasDataFlow(FunctionInput i, FunctionOutput o) { i.isParameter(0) and o.isReturnValue() } } // Track taint through `__getdelim`. class GetDelimFunction extends DataFlowFunction { GetDelimFunction() { this.getName().matches("%get%delim%") } override predicate hasDataFlow(FunctionInput i, FunctionOutput o) { i.isParameter(3) and o.isParameterDeref(0) } } class Config extends TaintTracking::Configuration { Config() { this = "fopen_to_alloca_taint" } override predicate isSource(DataFlow::Node source) { exists(FopenFunc ffc | source.asExpr() = ffc ) } override predicate isSink(DataFlow::Node sink) { exists(AllocaFunc af | sink.asExpr() = af.getArgument(0).getFullyConverted() and af.isUnsafeAlloc()) } } from DataFlow::PathNode source, DataFlow::PathNode sink, Config cfg where cfg.hasFlowPath(source, sink) select sink, source, sink, "fopen flows to alloca"
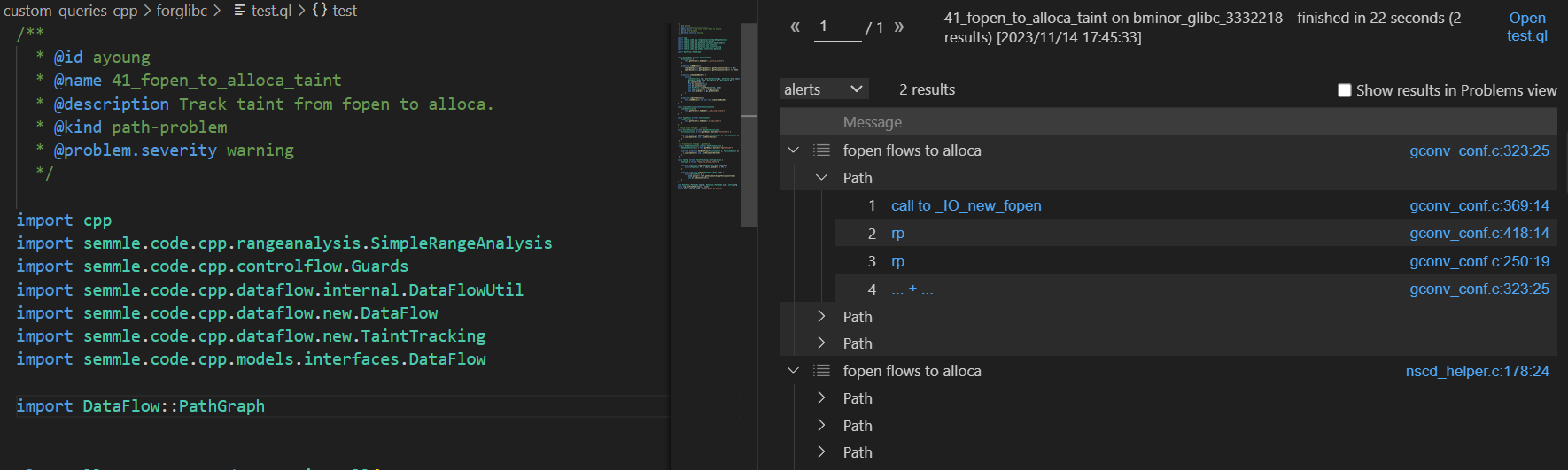 image-20231114174814502
image-20231114174814502
要点:
注释
@kind path-problem+import DataFlow::PathGraph+select sink, source, sink, "fopen flows to alloca"格式 使查询结果出现alert展示数据流路径 相关官方文档编写一个类扩展抽象类
DataFlowFunction,用于在没有源代码时对库函数进行准确的数据流建模。要使用这个QL库,创建一个扩展DataFlowFunction的QL类,并使用一个特征谓词来选择要建模的函数或函数集。在该类中,覆盖DataFlowFunction提供的谓词以匹配该函数中的流。也就是说上面两个DataFlowFunction是为了确保涉及strlen和getdelim的污点数据不被遗漏,hasDataFlow谓词限制输入输出,也就是污点数据流向
U-Boot Challenge
Step 0: Finding the definition of memcpy, ntohl, ntohll, and ntohs
import cpp from Function f where f.getName() = "strlen" select f
Question 0.0: Can you work out what the above query is doing? Hint: Paste it in the Query Console and run it.
Question 0.1: Modify the query to find the definition of memcpy. Hint: Queries have a from, where, and select clause. Have a look at this introduction to the QL language.
import cpp from Function f where f.getName() = "memcpy" select f
Question 0.2: ntohl, ntohll, and ntohs can either be functions or macros (depending on the platform where the code is compiled). As these snapshots for U-Boot were built on Linux, we know they are going to be macros. Write a query to find the definition of these macros. Hint: The CodeQL Query Console has an auto-completion feature. Hit Ctrl-Space after the from clause to get the list of objects you can query. Wait a second after typing myObject. to get the l ist of methods. Hint: We can use a regular expression to write a query that searches for all three macros at once.
import cpp from Macro m where m.getName() in ["ntohl", "ntohll", "ntohs"] select m
Step 1: Finding the calls to memcpy, ntohl, ntohll, and ntohs
Question 1.0
Find all the calls to memcpy. Hint: Use the auto-completion feature on the function call variable to guess how to express the relation between a function call and a function, and how to bind them.
import cpp from FunctionCall fc where fc.getTarget().getName() = "memcpy" select fc
Question 1.1
Find all the calls to ntohl, ntohll, and ntohs. Hint: calls to ntohl, ntohll, and ntohs are macro invocations, unlike memcpy which is a function call.
import cpp from MacroInvocation mi where mi.getMacroName() in ["ntohl", "ntohll", "ntohs"] select mi
Question 1.2
Find the expressions that resulted in these macro invocations. Hint: We need to get the expression of the macro invocation we found in 1.1
import cpp from MacroInvocation mi where mi.getMacroName() in ["ntohl", "ntohll", "ntohs"] select mi.getExpr()
Step 2: Data flow analysis
查找从网络读入的数据并最终被memcpy调用使用
Question 2.0
Write a QL class that finds all the top-level expressions associated with the macro invocations to the calls to ntohl, ntohll, and ntohs. Hint: Querying this class should give you the same results as in question 1.2
import cpp class NtFunc extends MacroInvocation{ NtFunc() { this.getMacroName() in ["ntohl", "ntohll", "ntohs"] } } from NtFunc nf select nf.getExpr()
Question 2.1
Create the configuration class, by defining the source and sink. The source should be calls to ntohl, ntohll, or ntohs. The sink should be the size argument of an unsafe call to memcpy. Hint: The source should be an instance of the class you wrote in part 2.0. Hint: The sink should be the size argument of calls to memcpy.
/** * @id ayoung * @name ntoh_to_memcpy_taint * @description Track taint from ntoh to memcpy. * @kind path-problem * @problem.severity warning */ import cpp import semmle.code.cpp.dataflow.new.TaintTracking import semmle.code.cpp.dataflow.new.DataFlow import DataFlow::PathGraph class NtFuncExpr extends Expr{ NtFuncExpr() { exists(MacroInvocation mi | mi.getMacro().getName() in ["ntohl", "ntohll", "ntohs"] and this = mi.getExpr()) } } class Config extends TaintTracking::Configuration { Config() { this = "NetworkToMemFuncLength" } override predicate isSource(DataFlow::Node source) { // exists(NtFuncExpr nfe | source.asExpr() = nfe ) source.asExpr() instanceof NtFuncExpr } override predicate isSink(DataFlow::Node sink) { exists(FunctionCall fc | sink.asExpr() = fc.getArgument(2) and fc.getTarget().hasName("memcpy") ) } } from DataFlow::PathNode source, DataFlow::PathNode sink, Config cfg where cfg.hasFlowPath(source, sink) select sink, source, sink, "ntoh flows to memcpy"
taintTracking用new时显示的结果32条,但是有的数据流很怪。去掉new则显示11条,数据流比较正常
Advanced dataflow scenarios for C/C++
当对字段的写入对CodeQL不可见时(例如,发生在定义不在数据库中的函数中),我们需要跟踪qualifier,并告诉数据流库它应该将流从限定符qualifier传输到字段访问field access。这是通过向数据流模块添加isAdditionalFlowStep谓词来完成的
当编写additional flow steps来跟踪指针时,您必须决定数据流步骤是应该从指针流出还是间接indirection流出。类似地,您必须决定附加步骤应该针对指针还是间接indirection指向指针。
Regular dataflow analysis
考虑数据从user_input()流出并且想知道数据是否能到达sink的参数
void sink(int); int user_input();
常规的数据流查询如下
/** * @kind path-problem */ import semmle.code.cpp.dataflow.new.DataFlow import Flow::PathGraph module Config implements DataFlow::ConfigSig { predicate isSource(DataFlow::Node source) { source.asExpr().(Call).getTarget().hasName("user_input") } predicate isSink(DataFlow::Node sink) { exists(Call call | call.getTarget().hasName("sink") and sink.asExpr() = call.getAnArgument() ) } } module Flow = DataFlow::Global<Config>; from Flow::PathNode source, Flow::PathNode sink where Flow::flowPath(source, sink) select sink.getNode(), source, sink, "Flow from user input to sink!"
能够捕捉大部分东西,比如:
struct A { const int *p; int x; }; struct B { A *a; int y; }; void fill_structure(B* b, const int* pu) { // ... b->a->p = pu; } void process_structure(const B* b) { sink(*b->a->p); } void get_and_process() { int u = user_input(); B* b = (B*)malloc(sizeof(B)); // ... fill_structure(b, &u); // ... process_structure(b); free(b); }
这个数据流很好匹配,因为codeql数据库包含要查看的信息:
- 用户输入从
user_input()开始,流入fill_structure - 数据写入对象b,访问路径为
[a, p] - 对象流出
fill_structure,并进入process_structure process_structure中读取路径[a, p],并在sink中接收
Flow from a qualifier to a field access
有时候字段访问对codeql来说是不可见的(比如,因为函数的实现不包含在数据库中),所以数据流无法讲所有存储与读取匹配起来,造成遗漏
例如,考虑另一种设置,其中我们的数据源作为write_user_input_to函数的输出参数开始。我们可以使用下面的isSource在数据流库中对这个设置建模
predicate isSource(DataFlow::Node source) { exists(Call call | call.getTarget().hasName("write_user_input_to") and source.asDefiningArgument() = call.getArgument(0) ) }
能够匹配下面例子对write_user_input_to的调用
void write_user_input_to(void*); void use_value(int); void* malloc(unsigned long); struct U { const int* p; int x; }; void process_user_data(const int* p) { // ... use_value(*p); } void get_and_process_user_input_v2() { U* u = (U*)malloc(sizeof(U)); write_user_input_to(u); process_user_data(u->p); free(u); }
使用isSource定义,数据流库沿着以下路径跟踪:
从write_user_input_to(...)的传出参数开始,继续到下一行的u->p
然而codeql在读取u->p之前没有观察到对p的写入,导致数据流在u中断
可以在字段读取中添加额外的流来纠正
/** * @kind path-problem */ import semmle.code.cpp.dataflow.new.DataFlow import Flow::PathGraph module Config implements DataFlow::ConfigSig { predicate isSource(DataFlow::Node source) { exists(Call call | call.getTarget().hasName("write_user_input_to") and source.asDefiningArgument() = call.getArgument(0) ) } predicate isSink(DataFlow::Node sink) { exists(Call call | call.getTarget().hasName("use_value") and sink.asExpr() = call.getAnArgument() ) } predicate isAdditionalFlowStep(DataFlow::Node n1, DataFlow::Node n2) { exists(FieldAccess fa | n1.asIndirectExpr() = fa.getQualifier() and n2.asIndirectExpr() = fa ) } } module Flow = DataFlow::Global<Config>; from Flow::PathNode source, Flow::PathNode sink where Flow::flowPath(source, sink) select sink.getNode(), source, sink, "Flow from user input to sink!"
注意isSource和isSink是如何按照预期的:我们寻找从write_user_input_to(...)的传出参数开始的流,并以isSink的参数结束。isAdditionalFlow制定了从一个FieldAccess的限定符qualifier到访问结果的流
实际查询中为确保不增加太多流会有限制(因为从字段限定符field qualifier到字段访问field access通常会产生大量虚假流),例如可以将fd限制为针对特定字段的字段访问(限制name),或是在特定结构类型中定义的字段的字段访问(限制type)
这里有一个重要的选择:n2应该是fa的指针值对应的节点,还是fa的间接值(即fa指向的值)
Using asIndirectExpr
如果我们用n2.asIndirectExpr() = fd,我们指定上面示例的流移动到fa指向的位置,这允许数据通过稍后的解引用dereference流动,而这正式我们在追踪从p到*p的数据流所需要的
再考虑一个略有不同的sink
void write_user_input_to(void*); void use_pointer(int*); void* malloc(unsigned long); struct U { const int* p; int x; }; void process_user_data(const int* p) { // ... use_pointer(p); } void get_and_process_user_input_v2() { U* u = (U*)malloc(sizeof(U)); write_user_input_to(u); process_user_data(u->p); free(u); }
和上一个例子唯一的区别是我们的数据最终进入了use_pointer函数调用,该函数接收一个int*而不是int作为参数
由于我们的isAdditionalFlowStep已经实现了FieldAccess的间接,所以已经跟踪了字段指向的内容,故可以通过sink.asIndirectExpr()找到数据
predicate isSink(DataFlow::Node sink) { exists(Call call | call.getTarget().hasName("use_pointer") and sink.asIndirectExpr() = call.getAnArgument() ) }
Using asExpr
另外,第二个例子中的流也可以被以下方式跟踪:
- 修改
isAdditionalFlowStep,使其针对代表FieldAccess的值而不是其指向的值 - 修改
isSink明确追踪实参传递给use_pointer的值(而不是实参指向的值)
/** * @kind path-problem */ import semmle.code.cpp.dataflow.new.DataFlow import Flow::PathGraph module Config implements DataFlow::ConfigSig { predicate isSource(DataFlow::Node source) { exists(Call call | call.getTarget().hasName("write_user_input_to") and source.asDefiningArgument() = call.getArgument(0) ) } predicate isSink(DataFlow::Node sink) { exists(Call call | call.getTarget().hasName("use_pointer") and sink.asExpr() = call.getAnArgument() ) } predicate isAdditionalFlowStep(DataFlow::Node n1, DataFlow::Node n2) { exists(FieldAccess fa | n1.asIndirectExpr() = fa.getQualifier() and n2.asExpr() = fa ) } } module Flow = DataFlow::Global<Config>; from Flow::PathNode source, Flow::PathNode sink where Flow::flowPath(source, sink) select sink.getNode(), source, sink, "Flow from user input to sink!"
当到达u->p时,增加的step将流从限定符qualifier指向的值传递到FieldAccess的结果,在此之后数据流流到user_pointer中的p,由于指定了isSink为实参的值,故最终找到结果
Passing the address of a variable to use_pointer
考虑另一种情况,U包含一个int数据,我们传递数据的地址给use_pointer
void write_user_input_to(void*); void use_pointer(int*); void* malloc(unsigned long); struct U { int data; int x; }; void process_user_data(int data) { // ... use_pointer(&data); } void get_and_process_user_input_v2() { U* u = (U*)malloc(sizeof(U)); write_user_input_to(u); process_user_data(u->data); free(u); }
因为data字段现在是一个int而不是int*,字段不再是indirection,所以没道理再用asIndirectExpr。所以只能污染字段的值
然而因为我们传递了data的地址给use_pointer,污点值是被use_pointer的参数指向的值(因为&data指向的值就是数据)
结合上述两点
- 使用
asExpr描述污点数据 - 选择参数的indirection
/** * @kind path-problem */ import semmle.code.cpp.dataflow.new.DataFlow import Flow::PathGraph module Config implements DataFlow::ConfigSig { predicate isSource(DataFlow::Node source) { exists(Call call | call.getTarget().hasName("write_user_input_to") and source.asDefiningArgument() = call.getArgument(0) ) } predicate isSink(DataFlow::Node sink) { exists(Call call | call.getTarget().hasName("use_pointer") and sink.asIndirectExpr() = call.getAnArgument() ) } predicate isAdditionalFlowStep(DataFlow::Node n1, DataFlow::Node n2) { exists(FieldAccess fa | n1.asIndirectExpr() = fa.getQualifier() and n2.asExpr() = fa ) } } module Flow = DataFlow::Global<Config>; from Flow::PathNode source, Flow::PathNode sink where Flow::flowPath(source, sink) select sink.getNode(), source, sink, "Flow from user input to sink!"
Specifying implicit reads
本节考虑,一个特定的字段被污染了,希望找到可能从该对象读取的任何位置,包括读取一组未知字段的任何位置
struct A { const int *p; int x; }; struct B { A *a; int z; }; int user_input(); void read_data(const void *); void *malloc(size_t); void get_input_and_read_data() { B b; b.a = (A *)malloc(sizeof(A)); b.a->x = user_input(); // ... read_data(&b); free(b.a); }
数据流:
通过访问路径[a, x]将一个用户控制的值写入对象b
b被传给数据库中没有定义的read_data
现在需要追踪这个流向read_data的用户输入
数据流库有一个特定的谓词来处理该场景,因此不需要用isAdditionalFlowStep添加流
相反,只需告诉数据流库read_data是一个sink且可以隐式地implicitly从传递给它的对象的字段读取数据。为此实现allowImplicitRead
/** * @kind path-problem */ import semmle.code.cpp.dataflow.new.DataFlow import Flow::PathGraph module Config implements DataFlow::ConfigSig { predicate isSource(DataFlow::Node source) { exists(Call call | call.getTarget().hasName("user_input") and source.asExpr() = call ) } predicate isSink(DataFlow::Node sink) { exists(Call call | call.getTarget().hasName("read_data") and sink.asIndirectExpr() = call.getAnArgument() ) } predicate allowImplicitRead(DataFlow::Node n, DataFlow::ContentSet cs) { isSink(n) and cs.getAReadContent().(DataFlow::FieldContent).getField().hasName(["a", "x"]) } } module Flow = DataFlow::Global<Config>; from Flow::PathNode source, Flow::PathNode sink where Flow::flowPath(source, sink) select sink.getNode(), source, sink, "Flow from user input to sink!"
allowImplicitRead谓词指定,如果再一个满足isSink节点,可以假设一个名为a或x的字段隐式读取
现在数据流库看到:
- 用户输入从
user_input()开始 - 数据通过访问路径
[a, x]流入b - 数据流入
&b的间接indirection(如对象b) - 隐式读取字段x,然后隐式读取sink处的字段a
最终就通过一个空的路径到达了满足isSink的节点,成功跟踪了完整的数据流
命令行方法
codeql query run
codeql query run -d hello_codedb hello.ql
codeql database analyze
没跑起来 出现:A fatal error occurred: Could not process query metadata for /home/ayoung/codeql/vscode-codeql-starter/codeql-custom-queries-cpp/hello.ql. Error was: Expected result pattern(s) are not present for problem query: Expected alternating entity/string and string columns. [INVALID_RESULT_PATTERNS]
最后select source.getNode().asExpr().(FunctionCall).getEnclosingFunction().toString(), "AAAA"时,query run有结果但database analyze跑通结果为空
#创建数据库 codeql database create databaseName --source-root=D:/xxljob --language=java #更新数据库 codeql database upgrade databaseName #执行扫描规则 codeql database analyze [databasePath] [rulesPath] --format=csv --output=result.csv #eg:codeql database analyze ./libtiff1_dbjob /root/Codeql/ql/codeql/cpp/ql/src/Security/CWE --format=csv --output=result.csv
docs
https://codeql.github.com/docs/codeql-language-guides/codeql-for-cpp/
https://codeql.github.com/docs/codeql-language-guides/codeql-library-for-cpp/ ,表格,一一对应数据结构与codeql class关系
misc
predicate,当前方法没有返回值
exist,子查询,是CodeQL谓词语法里非常常见的语法结构,它根据内部的子查询返回true or false,来决定筛选出哪些数据
source,漏洞污染输入点 sink,漏洞污染执行点