介绍
本文代码参考Linux-6.14.2
Ringing in a new asynchronous I/O API
io_uring 是 2019 年 Linux 5.1 内核首次引入的高性能 异步 I/O 框架,能显著加速 I/O 密集型应用的性能
与linux aio不同
- 设计上是真正异步的,在系统调用上下文中只是将请求放入队列,不会做其他任何额外的事情,保证应用永远不会阻塞
- 支持任何类型的I/O(cached files、direct-access files 甚至 blocking sockets),由于设计上就是异步的,无需poll+read/write来处理socket。只需提交一个阻塞式读,请求完成之后,就会出现在completing ring
- 灵活:基于
io_uring甚至能重写linux的每个系统调用
基本原理
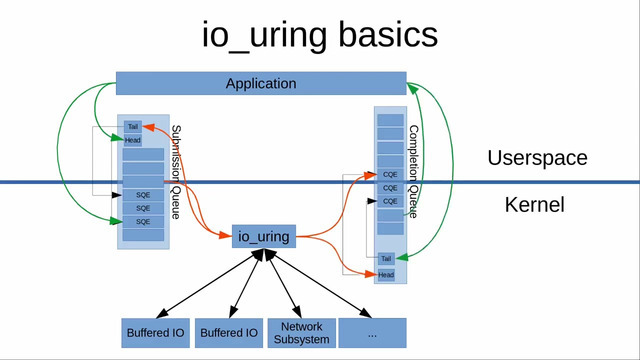
每个io_uring实例都有两个环形队列(ring),在内核和应用程序之间共享
- 提交队列:submission queue(SQ):请求提交方在该队列中放入I/O请求,由接收方取出请求进行处理
- 完成队列:completion queue(CQ):请求接收方在完成I/O请求后在该队列中放入处理结果,请求提交方通过读取该队列获取结果
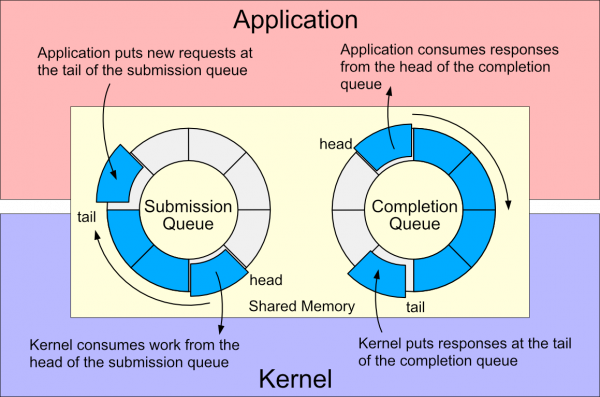
这两个队列都是单生产者、单消费者、size是2的幂次 提供无锁接口,内部使用内存屏障做同步
使用方式: 请求:
- 应用创建SQ entries(SQE),更新SQ tail
- 内核消费SQE,更新SQ head 完成
- 内核为完成的一个或多个请求创建CQ entries(CQE),更新CQ tail
- 应用消费CQE,更新CQ head
- 完成时间可能以任意顺序到达,但总是与特定SQE相关联
- 消费CQE过程无需切换到内核态
数据更新通过共享内存完成,整个过程采用异步、非阻塞、轮询思想
相关数据结构
内核中使用io_uring结构体保存单个环形队列的head和tail,head用于出队,tail用于入队,相等时队列空
struct io_uring { u32 head; u32 tail; };
io_uring_sqe结构体表示提交的请求(Submission Queue Entry) 定义部分如下,根据具体opcode选用不同共用体
/* * IO submission data structure (Submission Queue Entry) */ struct io_uring_sqe { __u8 opcode; /* type of operation for this sqe */ __u8 flags; /* IOSQE_ flags */ __u16 ioprio; /* ioprio for the request */ __s32 fd; /* file descriptor to do IO on */ // I/O优先级 union { __u64 off; /* offset into file 文件偏移量 */ __u64 addr2; struct { __u32 cmd_op; __u32 __pad1; }; }; union { __u64 addr; /* pointer to buffer or iovecs */ __u64 splice_off_in; // splice操作的输入偏移量 IORING_OP_SPLICE操作 struct { __u32 level; __u32 optname; }; }; __u32 len; /* buffer size or number of iovecs */ union { // ... 各种flags __u32 nop_flags; }; __u64 user_data; /* data to be passed back at completion time 用户数据 */ /* pack this to avoid bogus arm OABI complaints */ union { /* index into fixed buffers, if used */ __u16 buf_index; // 固定缓冲区索引 /* for grouped buffer selection */ __u16 buf_group; // 缓冲区组ID } __attribute__((packed)); //pakcet 避免ARM OABI填充问题 /* personality to use, if used */ __u16 personality; union { __s32 splice_fd_in; // splice操作的输入文件描述符 __u32 file_index; // 文件索引 __u32 optlen; struct { __u16 addr_len; // 地址结构长度 __u16 __pad3[1];// 填充 保持对齐 }; }; union { struct { __u64 addr3; __u64 __pad2[1]; }; struct { __u64 attr_ptr; /* pointer to attribute information */ __u64 attr_type_mask; /* bit mask of attributes */ }; __u64 optval; /* * If the ring is initialized with IORING_SETUP_SQE128, then * this field is used for 80 bytes of arbitrary command data */ __u8 cmd[0]; }; };
io_uring_cqe 结构体用来表示完成了的请求结果(Completion Queue Entry)
/* * IO completion data structure (Completion Queue Entry) */ struct io_uring_cqe { __u64 user_data; /* sqe->user_data value passed back */ __s32 res; /* result code for this event */ __u32 flags; /* * If the ring is initialized with IORING_SETUP_CQE32, then this field * contains 16-bytes of padding, doubling the size of the CQE. */ __u64 big_cqe[]; };
内核实际上使用一个io_rings结构体存储相应数据,其中封装了io_uring、提交队列sq、结果队列cq、cqe数组
/* * This data is shared with the application through the mmap at offsets * IORING_OFF_SQ_RING and IORING_OFF_CQ_RING. * 该数据通过mmap在偏移量IORING_OFF_SQ_RING和IORING_OFF_CQ_RING与应用共享 * * The offsets to the member fields are published through struct * io_sqring_offsets when calling io_uring_setup. * * 该成员字段偏移量由结构体io_sqring_offsets在调用io_uring_setup时提供 */ struct io_rings { /* * Head and tail offsets into the ring; the offsets need to be * masked to get valid indices. * head和tail是ring中的偏移;该偏移需要通过mask获取有效索引 * * The kernel controls head of the sq ring and the tail of the cq ring, * and the application controls tail of the sq ring and the head of the * cq ring. * 内核控制sq ring的head和cq ring的tail * 应用空只sq ring的tail和cq ring的head */ struct io_uring sq, cq; /* * Bitmasks to apply to head and tail offsets (constant, equals * ring_entries - 1) * 应用在head和tail偏移上的bitmasks(常量 等于ring_entries-1) */ u32 sq_ring_mask, cq_ring_mask; /* Ring sizes (constant, power of 2) 常量 2的幂次 */ u32 sq_ring_entries, cq_ring_entries; /* * Number of invalid entries dropped by the kernel due to * invalid index stored in array * 由于存放在数组中的无效下标被内核丢弃的无效entries数量 * * Written by the kernel, shouldn't be modified by the * application (i.e. get number of "new events" by comparing to * cached value). * 由内核写入,不应该被因公用修改(即通过与缓存值对比获取new events数量) * * After a new SQ head value was read by the application this * counter includes all submissions that were dropped reaching * the new SQ head (and possibly more). * 在一个新sq head值被应用读取后,该计数器包含所有到达新sq head时被丢弃的请求(可能更多) */ u32 sq_dropped; /* * Runtime SQ flags * * Written by the kernel, shouldn't be modified by the * application. * 由内核写入,不应被应用修改 * * The application needs a full memory barrier before checking * for IORING_SQ_NEED_WAKEUP after updating the sq tail. * 在更新sq tail之后检查IOURING_SQ_NEED_WAKEUP之前应用需要一个完整的内存屏障 */ atomic_t sq_flags; /* * Runtime CQ flags * * Written by the application, shouldn't be modified by the * kernel. * 应用写入,不应被内核修改 */ u32 cq_flags; /* * Number of completion events lost because the queue was full; * this should be avoided by the application by making sure * there are not more requests pending than there is space in * the completion queue. * 因为队列已满而丢失的已完成事件数量 * 应用程序应该通过确保挂起的请求不超过完成队列的空间来避免这种情况 * * Written by the kernel, shouldn't be modified by the * application (i.e. get number of "new events" by comparing to * cached value). * 由内核写入,不应被应用修改(即通过与缓存值对比获取new events数量) * * As completion events come in out of order this counter is not * ordered with any other data. */ u32 cq_overflow; /* * Ring buffer of completion events. * 已完成的时间缓冲区 * * The kernel writes completion events fresh every time they are * produced, so the application is allowed to modify pending * entries. * 内核每次生成完成事件时都会重新完整写入,因此应用程序可以修改待处理条目 */ struct io_uring_cqe cqes[] ____cacheline_aligned_in_smp; };
io_rings 与 io_uring_sqe 数组等其他相关数据结构实际上会被封装到 io_ring_ctx 结构体中,即 io_uring 上下文 ,这个结构体比较长 略
使用示例
apt安装liburing-dev
封装了io_uringi相关的操作
axboe/liburing
#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <unistd.h> #include <string.h> #include <liburing.h> #define BUF_SIZE 4096 #define FILE_PATH "test.txt" // 需要读取的文件 int main() { // 初始化io_uring struct io_uring ring; if (io_uring_queue_init(4, &ring, 0) != 0) { perror("io_uring_queue_init"); exit(1); } // 打开文件 int fd = open(FILE_PATH, O_RDONLY); if (fd < 0) { perror("open"); io_uring_queue_exit(&ring); exit(1); } // 准备缓冲区 char *buf = malloc(BUF_SIZE); if (!buf) { perror("malloc"); close(fd); io_uring_queue_exit(&ring); exit(1); } memset(buf, 0, BUF_SIZE); // 获取SQE(提交队列条目) struct io_uring_sqe *sqe = io_uring_get_sqe(&ring); if (!sqe) { perror("io_uring_get_sqe"); free(buf); close(fd); io_uring_queue_exit(&ring); exit(1); } // 设置读操作 io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0); io_uring_sqe_set_data(sqe, buf); // 关联缓冲区 // 提交请求 io_uring_submit(&ring); // 等待完成事件 struct io_uring_cqe *cqe; int ret = io_uring_wait_cqe(&ring, &cqe); if (ret < 0) { perror("io_uring_wait_cqe"); free(buf); close(fd); io_uring_queue_exit(&ring); exit(1); } // 处理结果 if (cqe->res < 0) { fprintf(stderr, "Read error: %s\n", strerror(-cqe->res)); } else { printf("Read %d bytes:\n", cqe->res); printf("%.*s", cqe->res, buf); // 安全打印 } // 清理 io_uring_cqe_seen(&ring, cqe); // 标记CQE已处理 free(buf); close(fd); io_uring_queue_exit(&ring); return 0; }
相关系统调用介绍
io_uring_setup()
该系统调用创建io_uring上下文,主要是创建一SQ队列与一个CQ队列,并指定queue元素数量至少为entries个;
返回一个文件描述符 供我们进行后续操作
SQ和CQ在应用和内核之间共享
int io_uring_setup(int entries, struct io_uring_params *params);
参数params用来配置io_uring,内核返回的SQ/CQ配置信息也通过它带回来
对应结构体定义如下
struct io_uring_params { __u32 sq_entries; __u32 cq_entries; __u32 flags; __u16 resv[10]; struct io_sqring_offsets sq_off; struct io_cqring_offsets cq_off; };
可以随后将该系统调用返回的fd传给mmap,来映射提交和完成队列
ring_fd即io_uring_setup()返回的文件描述符
加params.sq_off.array说明环不是正好从开头开始的
subqueue = mmap(0, params.sq_off.array + params.sq_entries*sizeof(__u32), PROT_READ|PROT_WRITE|MAP_SHARED|MAP_POPULATE, ring_fd, IORING_OFF_SQ_RING); sqentries = mmap(0, params.sq_entries*sizeof(struct io_uring_sqe), PROT_READ|PROT_WRITE|MAP_SHARED|MAP_POPULATE, ring_fd, IORING_OFF_SQES); cqentries = mmap(0, params.cq_off.cqes + params.cq_entries*sizeof(struct io_uring_cqe), PROT_READ|PROT_WRITE|MAP_SHARED|MAP_POPULATE, ring_fd, IORING_OFF_CQ_RING);
或传给io_uring_register()或io_uring_enter()系统调用
io_uring_register()
注册用于异步i/O的文件或用户缓冲区
int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);
注册文件或用户缓冲区,使内核能长时间持有对该文件在内核内部的数据结构引用,或创建应用内存的长期映射。这个操作只在注册的时候执行一次,因此减少了I/O开销
已经注册的缓冲区大小无法调整
io_uring_enter()
该系统调用用于初始化和完成I/O,使用共享的SQ和CQ 单次调用同时执行:
- 提交新的I/O请求
- 等待I/O完成
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);
fd是io_uring_setup()返回的文件描述符
to_submit指定了SQ中提交的I/O数量
模式:
- 默认模式 如果指定了
min_complete,会等待这个数量的I/O事件完成再返回 - 如果io_uring是polling模式,该参数表示:
- 0:要求内核返回当前以及完成的所有events,无阻塞
- 非零:如果由事件完成,内核仍然立即返回;如果没有完成事件,内核会轮询,等待指定的次数完成,或这个进程的时间片用完
深入系统调用
io_uring_setup()
创建 io_uring 上下文
SYSCALL_DEFINE2(io_uring_setup, u32, entries, struct io_uring_params __user *, params) { if (!io_uring_allowed()) return -EPERM; return io_uring_setup(entries, params); }
先将参数拷贝到内核中,检查resv数组为空和flags合法性
/* * Sets up an aio uring context, and returns the fd. Applications asks for a * ring size, we return the actual sq/cq ring sizes (among other things) in the * params structure passed in. */ static long io_uring_setup(u32 entries, struct io_uring_params __user *params) { struct io_uring_params p; int i; if (copy_from_user(&p, params, sizeof(p))) return -EFAULT; for (i = 0; i < ARRAY_SIZE(p.resv); i++) { if (p.resv[i]) return -EINVAL; } if (p.flags & ~(IORING_SETUP_IOPOLL | IORING_SETUP_SQPOLL | IORING_SETUP_SQ_AFF | IORING_SETUP_CQSIZE | IORING_SETUP_CLAMP | IORING_SETUP_ATTACH_WQ | IORING_SETUP_R_DISABLED | IORING_SETUP_SUBMIT_ALL | IORING_SETUP_COOP_TASKRUN | IORING_SETUP_TASKRUN_FLAG | IORING_SETUP_SQE128 | IORING_SETUP_CQE32 | IORING_SETUP_SINGLE_ISSUER | IORING_SETUP_DEFER_TASKRUN | IORING_SETUP_NO_MMAP | IORING_SETUP_REGISTERED_FD_ONLY | IORING_SETUP_NO_SQARRAY | IORING_SETUP_HYBRID_IOPOLL)) return -EINVAL; return io_uring_create(entries, &p, params); }
进入核心函数io_uring_create()
static __cold int io_uring_create(unsigned entries, struct io_uring_params *p, struct io_uring_params __user *params) { struct io_ring_ctx *ctx; struct io_uring_task *tctx; struct file *file; int ret; // 设置sq_entries和cq_entries,用结构体偏移填充sq_off和cq_off ret = io_uring_fill_params(entries, p); if (unlikely(ret)) return ret; // 分配ctx空间 kzalloc GFP_KERNEL ctx = io_ring_ctx_alloc(p); /** * ... * 初始化context * ... **/ // 分配 io_rings以及页面,这里会有很多内存分配 ret = io_allocate_scq_urings(ctx, p); // ... // SQ初始化相关 主要关于WQ和SQPOLL 包含很多操作 ret = io_sq_offload_create(ctx, p); // ... // 分配文件描述符 file = io_uring_get_file(ctx); // ... // 分配进程上下文(5.14特性) ret = __io_uring_add_tctx_node(ctx); //... }
其中分配io_uring_ctx等结构走的常规内存分配路径
static __cold struct io_ring_ctx *io_ring_ctx_alloc(struct io_uring_params *p) { struct io_ring_ctx *ctx; int hash_bits; bool ret; ctx = kzalloc(sizeof(*ctx), GFP_KERNEL); if (!ctx) return NULL; // ... }
具体到内部结构:
io_alloc_hash_table()函数中kvmalloc分配指针数组(GFP_KERNEL_ACCOUNT)
io_allocate_scq_urings()函数中
io_create_region() io_region_allocate_pages() io_mem_alloc_compound() alloc_pages_bulk_node()
io_mem_alloc_compound()走alloc_page()先对齐order再一次性分配指针数组页面后进行填充
alloc_pages_bulk_node()做页面分配,最终调用alloc_pages_bulk_noprof(),该函数用于批量分配order-0页面,存入参数page_array,并返回实际分配的页数
6.10之前,分配
io_rings通过io_mem_alloc()直接调用页级内存分配API
static int io_region_allocate_pages(struct io_ring_ctx *ctx, struct io_mapped_region *mr, struct io_uring_region_desc *reg, unsigned long mmap_offset) { gfp_t gfp = GFP_KERNEL_ACCOUNT | __GFP_ZERO | __GFP_NOWARN; unsigned long size = mr->nr_pages << PAGE_SHIFT; unsigned long nr_allocated; struct page **pages; void *p; pages = kvmalloc_array(mr->nr_pages, sizeof(*pages), gfp); if (!pages) return -ENOMEM; p = io_mem_alloc_compound(pages, mr->nr_pages, size, gfp); if (!IS_ERR(p)) { mr->flags |= IO_REGION_F_SINGLE_REF; goto done; } nr_allocated = alloc_pages_bulk_node(gfp, NUMA_NO_NODE, mr->nr_pages, pages); if (nr_allocated != mr->nr_pages) { if (nr_allocated) release_pages(pages, nr_allocated); kvfree(pages); return -ENOMEM; } done: reg->mmap_offset = mmap_offset; mr->pages = pages; return 0; } int io_create_region(struct io_ring_ctx *ctx, struct io_mapped_region *mr, struct io_uring_region_desc *reg, unsigned long mmap_offset) { int nr_pages, ret; u64 end; // ... nr_pages = reg->size >> PAGE_SHIFT; if (ctx->user) { ret = __io_account_mem(ctx->user, nr_pages); if (ret) return ret; } mr->nr_pages = nr_pages; if (reg->flags & IORING_MEM_REGION_TYPE_USER) // 用户提供页面 内核直接使用即可 // 将用户空间的内存区域固定到物理内存中,防止页面被换出 // mr 保存锁定页面的page指针数组 // 固定操作核心函数是__get_user_pages ret = io_region_pin_pages(ctx, mr, reg); else // 内核提供页面 ret = io_region_allocate_pages(ctx, mr, reg, mmap_offset); if (ret) goto out_free; ret = io_region_init_ptr(mr); if (ret) goto out_free; return 0; out_free: io_free_region(ctx, mr); return ret; } static __cold int io_allocate_scq_urings(struct io_ring_ctx *ctx, struct io_uring_params *p) { struct io_uring_region_desc rd; struct io_rings *rings; size_t size, sq_array_offset; int ret; /* make sure these are sane, as we already accounted them */ ctx->sq_entries = p->sq_entries; ctx->cq_entries = p->cq_entries; size = rings_size(ctx->flags, p->sq_entries, p->cq_entries, &sq_array_offset); if (size == SIZE_MAX) return -EOVERFLOW; memset(&rd, 0, sizeof(rd)); rd.size = PAGE_ALIGN(size); if (ctx->flags & IORING_SETUP_NO_MMAP) { rd.user_addr = p->cq_off.user_addr; rd.flags |= IORING_MEM_REGION_TYPE_USER; } ret = io_create_region(ctx, &ctx->ring_region, &rd, IORING_OFF_CQ_RING); if (ret) return ret; /* 与用户空间共享的 rings 本体 */ ctx->rings = rings = io_region_get_ptr(&ctx->ring_region); // ... if (p->flags & IORING_SETUP_SQE128) size = array_size(2 * sizeof(struct io_uring_sqe), p->sq_entries); else size = array_size(sizeof(struct io_uring_sqe), p->sq_entries); if (size == SIZE_MAX) { io_rings_free(ctx); return -EOVERFLOW; } memset(&rd, 0, sizeof(rd)); rd.size = PAGE_ALIGN(size); if (ctx->flags & IORING_SETUP_NO_MMAP) { rd.user_addr = p->sq_off.user_addr; rd.flags |= IORING_MEM_REGION_TYPE_USER; } ret = io_create_region(ctx, &ctx->sq_region, &rd, IORING_OFF_SQES); if (ret) { io_rings_free(ctx); return ret; } ctx->sq_sqes = io_region_get_ptr(&ctx->sq_region); return 0; }
这里正好看到这个io_region_pin_pages内部固定页面到物理内存中避免换出,这里深入看一下怎么做的
__get_user_pages调用链
__get_user_pages() follow_page_mask() follow_p4d_mask() follow_pud_mask() follow_pmd_mask() follow_page_pte() try_grab_folio()
当执行pin操作时,传入flags会有FOLL_PIN
// mm/gup.c int __must_check try_grab_folio(struct folio *folio, int refs, unsigned int flags) { // ... if (flags & FOLL_GET) folio_ref_add(folio, refs); else if (flags & FOLL_PIN) { /* * Don't take a pin on the zero page - it's not going anywhere * and it is used in a *lot* of places. */ if (is_zero_folio(folio)) return 0; /* * Increment the normal page refcount field at least once, * so that the page really is pinned. */ if (folio_test_large(folio)) { folio_ref_add(folio, refs); atomic_add(refs, &folio->_pincount); } else { folio_ref_add(folio, refs * GUP_PIN_COUNTING_BIAS); //here } node_stat_mod_folio(folio, NR_FOLL_PIN_ACQUIRED, refs); } return 0; }
// include/linux/mm.h #define GUP_PIN_COUNTING_BIAS (1U << 10) // include/linux/page_ref.h static inline void folio_ref_add(struct folio *folio, int nr) { page_ref_add(&folio->page, nr); }
所以实际上是加了特殊的的引用计数GUP_PIN_COUNTING_BIAS即1024
io_uring_register()
操作用于异步 I/O 的缓冲区
核心是__io_uring_register(),一个巨大的switch
static int __io_uring_register(struct io_ring_ctx *ctx, unsigned opcode, void __user *arg, unsigned nr_args) __releases(ctx->uring_lock) __acquires(ctx->uring_lock) { //... switch (opcode) { //... }
io_uring_enter()
提交新的 I/O 请求
用户空间可以通过io_uring_enter提交新的I/O请求,告诉内核已经在SQ队列提交了SQE,可以选择是否等待I/O完成等选项
SYSCALL_DEFINE6(io_uring_enter, unsigned int, fd, u32, to_submit, u32, min_complete, u32, flags, const void __user *, argp, size_t, argsz)
IORING_REGISTER_BUFFERS2 :老版本内核中的 4k “菜单堆”
本小节以6.3.9代码为例 新版内核中该功能实现存在很多改动,自该版本起不再存在4k内存页分配
分配(GFP_KERNEL_ACCOUNT)
指定opcode为IORING_REGISTER_BUFFERS2时,对应io_register_rsrc()处理,最终调用到io_rsrc_data_alloc():
- 首先分配一个
io_rsrc_data结构体(GFP_KERNEL,大小80,kmalloc-96) - 接着分配一个指针数组
table,根据传入的size分配对应数量的大小为4k的内核对象,分配flag为GFP_KERNEL_ACCOUNT
由于这里size是可控的,故可以通过控制size来控制指针数组的大小以及分配的4k内核对象数量
static __cold void **io_alloc_page_table(size_t size) { unsigned i, nr_tables = DIV_ROUND_UP(size, PAGE_SIZE); /* 向上按页大小对齐 */ size_t init_size = size; void **table; table = kcalloc(nr_tables, sizeof(*table), GFP_KERNEL_ACCOUNT); if (!table) return NULL; for (i = 0; i < nr_tables; i++) { unsigned int this_size = min_t(size_t, size, PAGE_SIZE); table[i] = kzalloc(this_size, GFP_KERNEL_ACCOUNT); if (!table[i]) { io_free_page_table(table, init_size); return NULL; } size -= this_size; } return table; } __cold static int io_rsrc_data_alloc(struct io_ring_ctx *ctx, rsrc_put_fn *do_put, u64 __user *utags, unsigned nr, struct io_rsrc_data **pdata) { struct io_rsrc_data *data; int ret = 0; unsigned i; data = kzalloc(sizeof(*data), GFP_KERNEL); if (!data) return -ENOMEM; data->tags = (u64 **)io_alloc_page_table(nr * sizeof(data->tags[0][0]));
完成分配后进行数据拷贝操作,4k内核对象可以全部存储来自用户空间的数据,具体而言就是通过copy_from_user将用户态传入的utags拷贝到刚刚分配的data->tags中,拷贝方式是八字节八字节拷贝
data->nr = nr; data->ctx = ctx; data->do_put = do_put; if (utags) { ret = -EFAULT; for (i = 0; i < nr; i++) { u64 *tag_slot = io_get_tag_slot(data, i); if (copy_from_user(tag_slot, &utags[i], sizeof(*tag_slot))) goto fail; } } atomic_set(&data->refs, 1); init_completion(&data->done); *pdata = data; return 0; fail: io_rsrc_data_free(data); return ret; } static inline u64 *io_get_tag_slot(struct io_rsrc_data *data, unsigned int idx) { unsigned int off = idx & IO_RSRC_TAG_TABLE_MASK; unsigned int table_idx = idx >> IO_RSRC_TAG_TABLE_SHIFT; return &data->tags[table_idx][off]; }
该函数有一定程度的额外分配噪音
int io_sqe_buffers_register(struct io_ring_ctx *ctx, void __user *arg, unsigned int nr_args, u64 __user *tags) { // ... ret = io_rsrc_data_alloc(ctx, io_rsrc_buf_put, tags, nr_args, &data); if (ret) return ret; ret = io_buffers_map_alloc(ctx, nr_args); /* 噪音 */ if (ret) { io_rsrc_data_free(data); return ret; } // ... }
编辑(update)
完成4k对象的分配后,可以通过IORING_REGISTER_BUFFERS_UPDATE这个opcode更新其中的数据
核心调用到__io_sqe_buffers_update()函数
static int __io_sqe_buffers_update(struct io_ring_ctx *ctx, struct io_uring_rsrc_update2 *up, unsigned int nr_args) { // ... for (done = 0; done < nr_args; done++) { struct io_mapped_ubuf *imu; int offset = up->offset + done; u64 tag = 0; err = io_copy_iov(ctx, &iov, iovs, done); if (err) break; if (tags && copy_from_user(&tag, &tags[done], sizeof(tag))) { err = -EFAULT; break; } // ... }
读取/写入(read/write)
可以通过io_uring本身的功能提交SQE将数据从文件中拷贝到缓冲区,或者从缓冲区读取到文件
可以在用户空间使用管道来将这些 4k 缓冲区的数据读取到用户空间,或是将管道/文件中的数据写入这些内核缓冲区
释放
和register对应,也有unregister功能,可以通过IORING_UNREGISTER_BUFFERS
最后调用到io_rsrc_data_free()释放资源
static void io_free_page_table(void **table, size_t size) { unsigned i, nr_tables = DIV_ROUND_UP(size, PAGE_SIZE); for (i = 0; i < nr_tables; i++) kfree(table[i]); kfree(table); } static void io_rsrc_data_free(struct io_rsrc_data *data) { size_t size = data->nr * sizeof(data->tags[0][0]); if (data->tags) io_free_page_table((void **)data->tags, size); kfree(data); }
数据泄露
由于指针数组table中存放的就是指向内核对象的指针,该对象使用的是通用的分配flagGFP_KERNEL_ACCOUNT,可以通过读取指针数组泄露内核队地址
任意地址写
若能修改指针数组中存放的指针,即可通过update功能进行任意地址写
copy_from_user()
例题
- [[译] Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020)]
- 0x0C-io-uring-与异步-IO-相关
- io_uring在kernel pwn中的优异表现